Исследовательская компания Arthur AI протестировала модели искусственного интеллекта от Meta, OpenAI, Cohere и Anthropic, проанализировав, какие из них чаще выдумывают факты или галлюцинируют.
Курс UI/UX Design. Закохайте своїх користувачів у ваш дизайн! Виглядайте стильно та перетворюйте їх у вірних прихильників! Ознайомитись з курсом
Кратко подытожив результаты, можно сделать вывод, что GPT-4 от OpenAI (с поддержкой Microsoft) станет лучшим помощником в математических вопросах. Claude 2 от Anthropic лучше всех понимает свои лимиты и места, где он может сделать ошибки. Command AI Cohere чаще всего галлюцинирует, а Llama 2 от Meta посредственный во всех пока выполненных тестах.
Hallucination Experiment
Большие языковые модели (LLM) захватили мир штурмом, но они не являются безупречным источником истины. В Arthur & Partners стремились исследовать количественно и качественно, как некоторые из LLM отвечают на сложные вопросы. Собрали наборы сложных вопросов (а также ожидаемые ответы) из трех категорий: комбинаторная математика, президенты США и политические лидеры Марокко. Вопросы были разработаны таким образом, чтобы содержать ключевой компонент, который заставляет LLM ошибаться: они требуют достигать ответа путем нескольких этапов рассуждений.
Тестировали модели gpt-3.5 (~175 млрд параметров) и gpt-4 (~1,76 триллиона параметров) от OpenAI, claude-2 от Anthropic (# неизвестно), llama-2 (70 млрд параметров) от Meta и модель Command от Cohere (~50 млрд параметров).

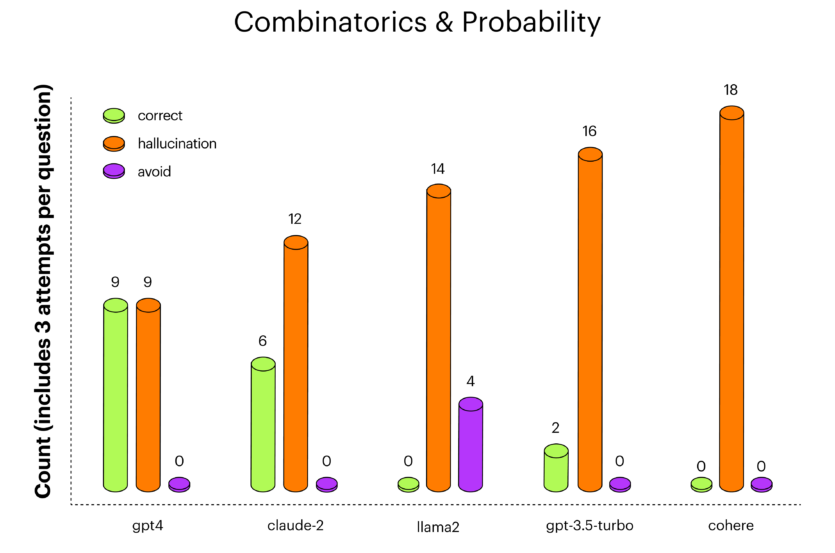
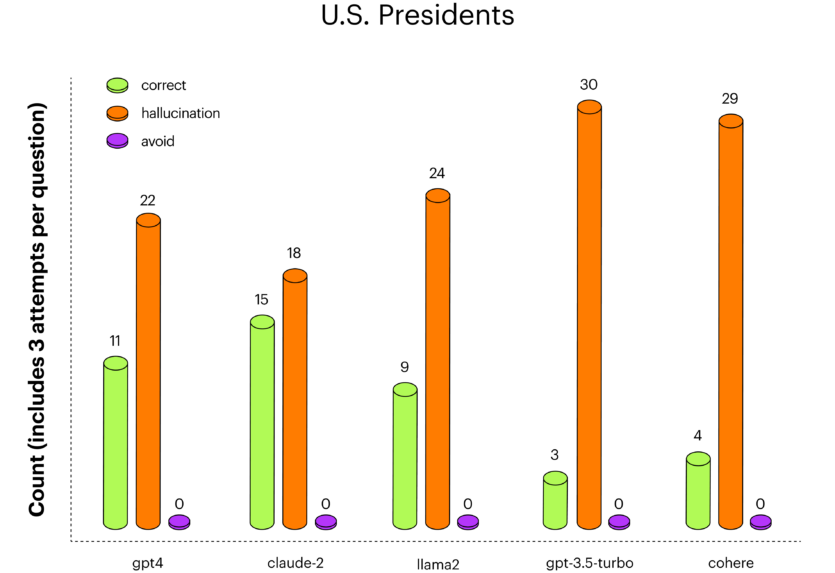
На комбинаторике gpt-4 показал лучшие результаты, за ним следовал claude-2. На президентах США claude-2 дает больше правильных ответов, чем gpt-4, неплохо показала себя большая языковая модель llama-2.
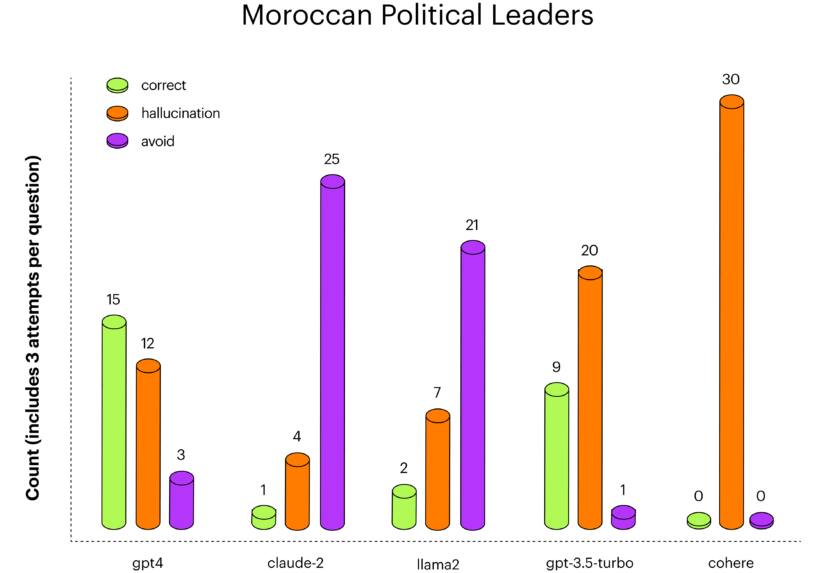
По марокканским политическим лидерам gpt-4 показал лучшие результаты, а claude-2 и llama-2 воздержались от ответа почти на все вопросы.
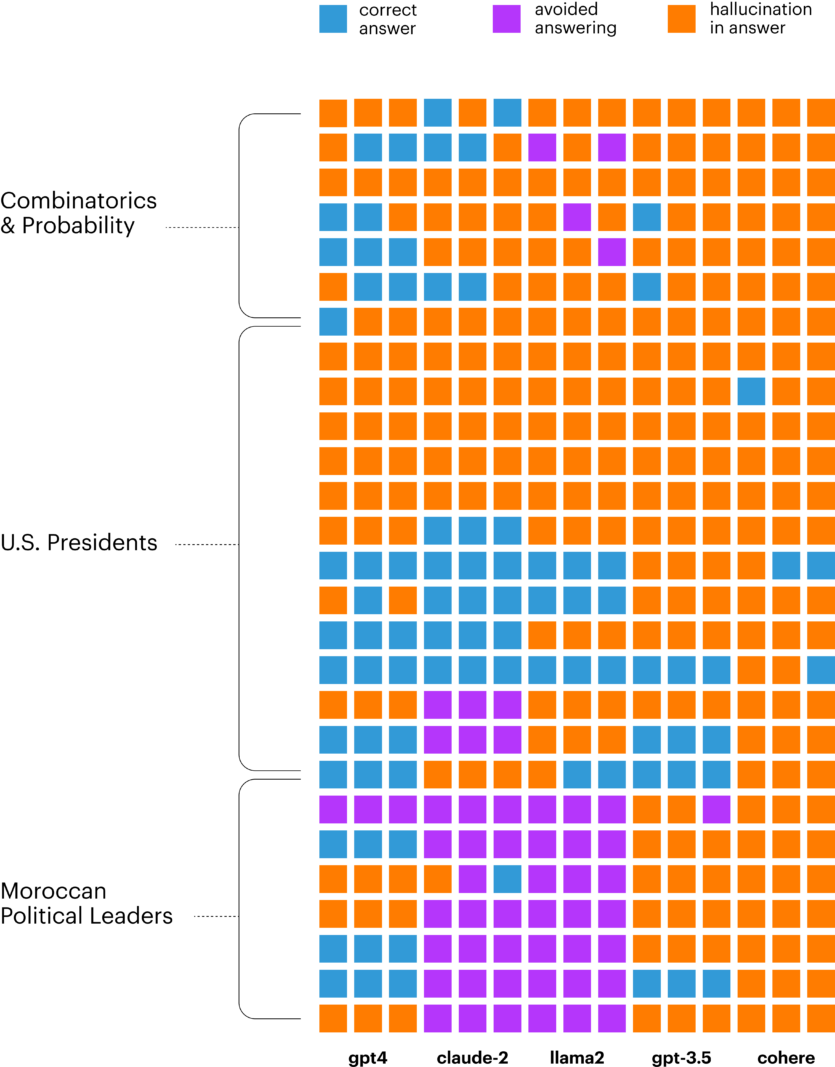
Во время нескольких попыток может быть разнообразие в типах ответов LLM: на один и тот же вопрос модель могла иногда отвечать правильно, иногда — немного неправильно, иногда — совсем не правильно, а иногда избегать ответа.
БлогиChatGPT на конкурсі блогів ITC.UA  https://itc.ua/wp-content/uploads/2023/08/Bezymyannyj-150×150.png *** https://itc.ua/wp-content/uploads/2023/08/Bezymyannyj-150×150.png *** https://itc.ua/wp-content/uploads/2023/08/Bezymyannyj-150×150.png
https://itc.ua/wp-content/uploads/2023/08/Bezymyannyj-150×150.png *** https://itc.ua/wp-content/uploads/2023/08/Bezymyannyj-150×150.png *** https://itc.ua/wp-content/uploads/2023/08/Bezymyannyj-150×150.png
Ydri
блогер
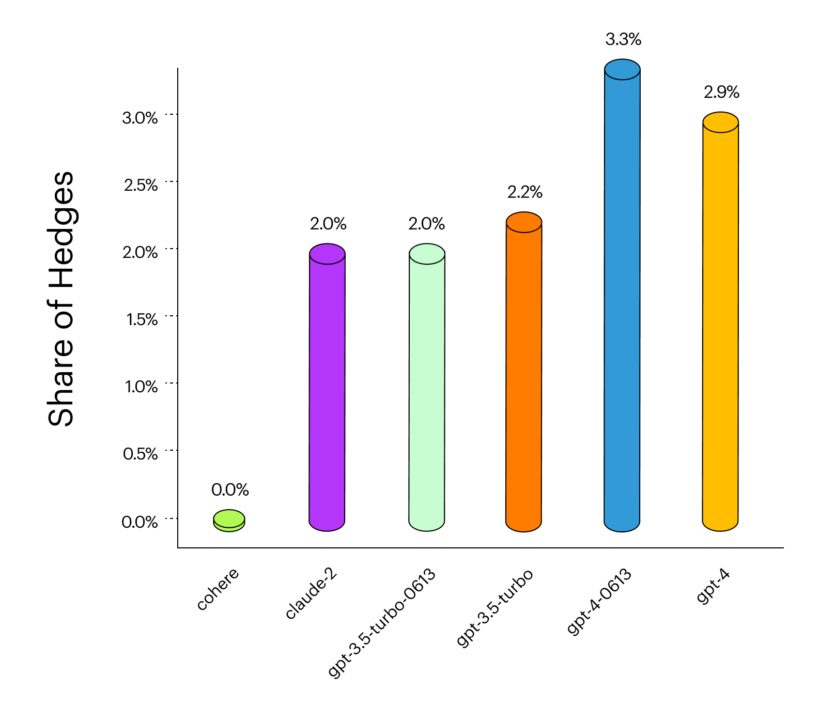
Hedging Answers Experiment
Одновременно разработчики обеспокоены тем, что модели генерируют некорректный, токсичный или оскорбительный контент. Чтобы уменьшить этот риск, разработчики научили модели добавлять предупреждающие сообщения к сгенерированным ответам. Например, LLM часто отвечают: «Как ИИ-модель я не могу выражать свое мнение», «К сожалению, я не могу ответить на этот вопрос» и т. д.
Хотя такие «хеджевые» ответы иногда уместны (и являются хорошим поведением по умолчанию), они также могут разочаровывать пользователей, которые ожидают прямого ответа от ИИ.
Этот эксперимент проверил, как часто самые распространенные модели реагируют «хеджевыми» ответами.

Оказалось, что доля ответов «хеджирование» возросла для моделей OpenAI (GPT-3.5 против GPT-4). Это количественно отражает показания пользователей о том, что GPT-4 стала более неприятной в использовании, чем GPT-3.5.
Cohere не включает язык хеджирования ни в один из своих ответов, который может быть уместным или неуместным в зависимости от заданного вопроса.
В Associated Press установили правила использования ИИ для журналистов – ChatGPT советуют «избегать»



")


")















{kind=link}